Traitement de fichiers texte en ligne de commande sous Linux
Cet article expose les différentes possibilités existantes sous Linux pour générer, modifier, trier ou filtrer un fichier texte. On utilisera ici les différents utilitaires présents dans un shell Linux.
Liste des utilitaires utilisés
Voici les différents programmes que nous utiliserons dans le shell Linux. Ces commandes ne seront pas présentées ici de manière exaustive en donnant l'ensemble de leur syntaxe, mais seront utilisées dès qu'elles seront utiles.
Commande |
|
D'autres commandes bien pratiques existent encore dans un shell Linux et sont utilisables dans un tube afin de filtrer, traiter, analyser, convertir ou ré-organiser un fichier texte ou la sortie standard d'une autre commande. Citons par exemple tsort, expand, unexpand, join, look, wc, fold, fmt, col, column, colrm, gettext, msgfmt, (et tous les programmes msg*), iconv, recode, tex, gs, texexec, enscript, groff, tbl, eqn, lex, flex, yacc, bison, etc.
Comment connaître le shell dans lequel on travaille ?
Pour connaître le shell courant dans lequel on travaille il faut consulter le fichier /proc/$$/cmdline :
cat /proc/$$/cmdline
Pour connaître la version du shell bash :
bash --version
Pour toutes les expériences exposées sur cette page j'ai utilisé le shell bash version 4.3.8 d'Ubuntu.
Filtrage des caractères aléatoires du périphérique /dev/urandom
Nous partons du périphérique aléatoire /dev/urandom qui génère un nombre quelconques de caractères de valeur comprise entre 0 et 255.
L'ensemble des exemples donnés ci-dessous représente une expérience à réaliser dans un shell Linux afin de bien se rendre compte de l'action de chaque commande.
Si on affiche tous le contenu du fichier /dev/urandom on obtient une infinité de caractères quelconques à l'écran (dont des caractères de contrôles indésirables qui pourraient être interprétés par le shell) :
cat /dev/urandom
Filtrons les caractères afin de ne garder que des lettres minuscules grâce à la commande tr :
cat /dev/urandom | tr -d -c "a-z"
On peut aussi demander tous les caractères alphanumériques (lettres minuscules, lettres majuscules et chiffres) :
cat /dev/urandom | tr -d -c "a-zA-Z0-9"
Mais on obtient une ligne unique, de longueur infinie. Ajoutons le caractères fin de ligne \n afin d'obtenir plusieurs lignes alphanumériques :
cat /dev/urandom | tr -d -c "a-zA-Z0-9\n"
On obtient maintenant des lignes de longueur quelconque. Gardons seulement les 80 premiers caractères de chaque ligne grâce à la commande cut qui permet de couper une chaîne de caractères :
cat /dev/urandom | tr -d -c "a-zA-Z0-9;\n" | cut -c 1-80
On obtient alors des lignes contenant entre 0 et 80 caractères. Afin de ne garder que les lignes contenant 80 caractères, filtrons l'ensemble des lignes grâce à la commande egrep et demandons de ne garder que les lignes contenant exactement 80 caractères en utilisant une expression régulière :
cat /dev/urandom | tr -d -c "a-zA-Z0-9\n" | cut -c 1-80 | egrep '^.{80}$'
Afin que les lignes soient divisées en champs séparés par un point-virgule, ajoutons le caractère point-virgule dans la sélection des caractères gardés à partir du flux aléatoire arrivant de /dev/urandom :
cat /dev/urandom | tr -d -c "a-zA-Z0-9;\n" | cut -c 1-80 | egrep '^.{80}$'
On obtient des lignes contenant exactement 80 caractères et avec un nombre quelconque de caractères point-virgule. Si on ne veut pas de champs vides, il faut éliminer les lignes commençant par ;, finissant par ;, ou contenant plusieurs point-virgules consécutifs. Supprimons ces lignes indésirables grâce à l'option -v de egrep qui n'affiche pas les lignes correspondant à l'expression régulière étendue :
cat /dev/urandom | tr -d -c "a-zA-Z0-9;\n" | cut -c 1-80 | egrep '^.{80}$' | egrep -v '^;' | egrep -v ';$' | egrep -v ';;'
Cette fois on obtient des lignes de 80 caractères alphanumériques, divisées en champs avec le point-virgule comme séparateur, et sans champs vides. Mais le nombre de champs et leur taille est totalement aléatoire. Pour régler le nombre et la taille des champs nous allons utiliser une dernière expression régulière étendue précisant le nombre et la taille des champs :
cat /dev/urandom | tr -d -c "a-zA-Z0-9;\n" | cut -c 1-80 | egrep '^.{80}$' | egrep '^[^;]{6,}(;[^;]{6,}){4}$'
Dans l'expression régulière étendue ^[^;]{6,}(;[^;]{6,}){4}$ :
^[^;]{6,} impose que le premier champs (tout caractère sauf ; au début de la ligne) ait une taille de 6 caractères ou plus.
(;[^;]{6,}){4} impose de trouver exactement 4 champs après le premier dans la ligne
Ainsi on récupère seulement les lignes contenant exactement 5 champs, avec des champs possédant au moins 6 caractères. Cette dernière expression régulière étendue supprime naturellement les lignes commençant par ;, finissant par ;, ou contenant plusieurs point-virgules consécutifs, d'où le supression des 3 commandes egrep -v précédentes.
Enfin parmi toutes les lignes générées, si on n'en veut que 10, il suffit de demander à head de n'afficher que les 10 premières lignes du flux :
cat /dev/urandom | tr -d -c "a-zA-Z0-9;\n" | cut -c 1-80 | egrep '^.{80}$' | egrep '^[^;]{6,}(;[^;]{6,}){4}$' | head -10
Exemple de lignes obtenues :
fyIxXqeUFNwGNCN1A;g6DQlU;KRBo343L;ax0EpVByuma;5XUg8goKVw6BAMJSb5Ly6Q1pj2jso5698s
iMvjNLVwPsW;JXE1boGbI6Ua0;4altLvxm26GPxBil;o9LarDMM9T7LDLKDASGB2ZThBz;e8EPWrHE1P
zi7AGYBhDewhGQXLgNE;bBqR1t8mzgDfvgQcGJ1h;146jrtaz;Rc2nLzEN2;XizsWtHTmIySxECn4a0Q
pJNrJVcy;tbYGsBUZMY2bymsME9Ta8Sn8Lc8Ed3i;tJbVsFoNE6;qGug5Nt7SCzsr7niJYEvV;KXHvqi
TCXDXSELsEv04fs6yGe5u4PxP6Cpl;Ew1OIMi6zZnEFhJq;gVrkDgcRVd;VnPdYa;26VkDET56mkD4zz
fDv0Tp;aRwtdcWDiH274I2auDUXlpS;2XXwWbsgA8Fb1;YuokRli6kaI8sWIN9XOHqPKSIkuG;ExdDde
FQnAGcL;iX3JRpXVxI6GXcMc6O7QZR3LzhukvfUNS;c7PG9FZ23ueZ896LXMKrYFy;TZKUOX;WmT75gn
Qn3eeajPj;32NkA1Vn;bE7W4mlnW9a4M2b2Op;HI52N9MI33hHFo5n0tEEMWx;lfAQUYM6n9AURAChGk
y9zLiZGRarexBl33aFtMzy0UocHl4uK;oG5DrAd0Iulpt575;moL5fa0QX3r5;aqgHjU4PgeW;iIoqmc
wOB4Sj4bVwu69ef;aFtI9Aopfd;NlR1BbRpVtkpKihZOufE1y2wQcpZEvRkVcoC;u4fp1jw;59Lb4wWF
Cette première expérience a montré comment filtrer le flux de caractères aléatoires /dev/urandom afin de ne garder que :
- un nombre précis de lignes
- contenant un nombre donné de caractères
- divisées en un nombre donné de champs
- séparés par un séparateur donné
- contenant seulement certains caractères
- les champs devant posséder un nombre minimal de caractères
Application : si on désire obtenir des lignes contenant exactement 8 champs composés chacun de 4 chiffres on lancera la commande :
cat /dev/urandom | tr -d -c "0-9;\n" | egrep '^[^;]{4}(;[^;]{4}){7}$'
Exemple de ligne obtenue :
5269;4102;8865;7456;3320;1205;9547;2008
Comme la taille et le nombre de champs sont indiqués en fixe dans l'expression régulière les lignes feront forcément 39 caractères et il devient alors inutile de filtrer seulement les lignes à 39 caractères (avec cut -c 1-39 et egrep '^.{39}$' dans le tube).
Mais cette fois on peut attendre longtemps avant qu'une ligne corresponde aux critères précis imposés par l'expression régulière : on compte sur le hasard le plus total pour obtenir les lignes formatées. Il serait plus efficace de filtrer les chiffres, on en fait des paquets de 4 pour former un champs, puis on regroupe les champs par 8 pour former une ligne.
Pour cela il y a plusieurs solutions en utilisant différentes commandes dans le shell Linux. En voici 5 parmi bien d'autres :
Solution 1 :
Demandons les lignes composées de 32 chiffres :
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{32}$'
Puis insérons les point-virgules tout les 4 caractères grâce à sed :
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{32}$' | sed 's/^\(....\)\(....\)\(....\)\(....\)\(....\)\(....\)\(....\)\(....\)$/\1;\2;\3;\4;\5;\6;\7;\8/'
Solution 2 :
On demande les 8 champs composés de 4 chiffres chacun :
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -8
Puis on met à plat le fichier obtenu grâce à paste en spécifiant le point-virgule comme séparateur :
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -8 | paste -s -d ";"
Mais cette commande ne nous donne qu'une seule ligne pour le fichier de sortie. Pour obtenir plusieurs lignes on va lancer plusieurs fois cette commande en la plaçant dans une boucle for. Exemple pour obtenir 50 lignes :
for ((i=0;i<50;i++)); do cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -8 | paste -s -d ";"; done
Solution 3 :
On crée 8 fichiers de 50 lignes contenant chacun une seule colonne de 4 chiffres :
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -50 > fic1
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -50 > fic2
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -50 > fic3
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -50 > fic4
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -50 > fic5
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -50 > fic6
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -50 > fic7
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -50 > fic8
Puis on concatène les 8 fichiers en un seul gâce à paste en spécifiant le point-virgule comme séparateur de champs :
paste -d ";" fic1 fic2 fic3 fic4 fic5 fic6 fic7 fic8
Remarque : paste accepte le caractère * pour concaténer un ensemble de fichier possédant la même base dans leur nom :
paste -d ";" fic*
Solution 4 :
On crée un fichier de 64 lignes avec une seule colonne de 4 chiffres, puis on l'affiche grâce à pr en demandant 8 colonnes et en spécifiant le caractère point-virgule comme séparateur et on ne garde que les 8 premières lignes parmi celles contenant des chiffres :
cat /dev/urandom | tr -d -c "0-9\n" | egrep '^.{4}$' | head -64 | pr -c8 -l 20 -s";" | grep '[0.9]' | tail -8
En modifiant la ligne de commande ci-dessus on peut facilement régler le nombre et la taille des champs, les caractères retenus pour composer les champs, le séparateur entre les champs ou encore le nombre de lignes générées.
Exemple de fichier obtenu :
9667;2188;8196;1353;0950;4455;7372;1262
9921;2460;9037;9657;2817;6701;0532;7065
2210;4116;6997;5914;3181;4692;8515;0083
4831;1471;3368;5072;0405;0664;6761;6683
3627;1981;3709;4420;1052;1911;2905;5650
6033;7436;7628;1467;2234;2615;1243;6533
3460;5737;2497;5146;7767;1860;3397;1470
0925;8135;3601;7263;7902;1107;2411;6269
Solution 5 :
On filtre les caractères arrivant du générateur aléatoire afin de ne garder que les chiffres et le retour à la ligne. Parmi toutes ces lignes on n'en garde que quelques unes grâce à head (exemple : seulement les 8 premières lignes). Enfin on met à plat (sans séparateur) ces 8 lignes grâce à paste à la fin du tube ce qui donne une unique ligne, ne contenant que des chiffres et finissant par un retour à la ligne :
cat /dev/urandom | tr -d -c "0-9\n" | head -8 | paste -s -d ""
Sur cette unique ligne on ne garde que les 4 premiers caractères grâce à cut à la fin du tube ce qui nous donne un champs :
cat /dev/urandom | tr -d -c "0-9\n" | head -8 | paste -s -d "" | cut -c1-4
Pour obtenir 8 champs on répète 8 fois la ligne de commande précédente grâce à une boucle for :
for ((i=0;i<8;i++)); do cat /dev/urandom | tr -d -c "0-9\n" | head -8 | paste -s -d "" | cut -c1-4; done
On met à plat les 8 champs grâce à paste en précisant le point-virgule comme séparateur de champs :
for ((i=0;i<8;i++)); do cat /dev/urandom | tr -d -c "0-9\n" | head -8 | paste -s -d "" | cut -c1-4; done | paste -s -d ";"
Enfin si on veut 20 lignes (par exemple) on répète 20 fois la ligne de commande précédente grâce à une nouvelle boucle for :
for ((j=0;j<20;j++)); do for ((i=0;i<8;i++)); do cat /dev/urandom | tr -d -c "0-9\n" | head -8 | paste -s -d "" | cut -c1-4; done | paste -s -d ";"; done
En modifiant la ligne de commande ci-dessus on peut facilement régler le nombre et la taille des champs, les caractères retenus pour composer les champs, le séparateur entre les champs ou encore le nombre de lignes générées.
Exemple de fichier obtenu :
7305;2248;7227;5841;9224;7754;7168;8332
5668;1569;7985;7229;3774;1991;5307;8321
0269;1617;0418;7292;6923;0782;3919;8467
4371;3071;2320;5706;7675;4353;1324;8547
2619;5031;0670;4163;8012;7351;7972;3479
3714;5829;8752;5533;3470;3780;1087;3163
7219;7711;3385;5724;6731;6813;6633;1804
1856;7860;0831;1033;6441;8623;7945;1719
2703;6315;8835;7394;0665;4752;5241;2537
7047;6968;3251;2290;7515;8376;2429;1291
3930;0361;4622;4333;0650;6889;8895;5597
7205;2316;1128;5779;6092;7717;7796;6003
2559;0040;9434;9071;2741;3836;5263;9780
5591;8467;7781;8500;9032;3316;0230;7894
7391;0149;5089;5109;1992;5548;3505;2886
4379;9795;8354;5041;1007;5753;2715;1176
3898;5796;2892;5892;0978;1084;1417;5595
7374;4042;9620;3474;3172;6747;6231;5934
6973;0420;3950;4288;4920;0860;4415;4812
5425;6195;4036;4050;5904;3947;0304;5522
Biensûr pour obtenir un tel fichier il est plus simple d'utiliser un langage de programmation impératif comme Python, Perl, Ruby ou JavaScript par exemple. L'objectif de ce paragraphe est de montrer les différentes possibilités des commandes tubes et filtres disponibles en ligne de commande dans un shell Linux permettant le traitement fin d'informations textuelles.
Autre application : un générateur de calendrier réalisé dans un shell Linux
Nous partons cette fois de la sortie standard de la commande date. En filtrant les données textuelles données par date, il est facile d'obtenir un générateur de calendrier configurable nous donnant tout type de calendrier (ex : obtenir tous les jours d'une année, obtenir tous les mardis d'une année scolaire, obtenir tous les 1er mai des 10 ans à venir, etc.). Nous verrons ensuite comment calculer la date de tous les jours fériés d'une année quelconque, toujours en utilisant exclusivement les commandes présentes dans un shell Linux.
Commençons par voir la syntaxe de base de la commande date dans un shell Linux :
Par défaut la commande date sans paramètre renvoie la date et l'heure actuelle du système :
$ date
vendredi 25 avril 2014, 16:12:00 (UTC+0200)
Grâce à une chaîne commençant par + il est possible de formater l'affichage :
$ date "+%A %d %B %Y"
vendredi 25 avril 2014
Grâce au paramètre -d il est possible de passer à date une date quelconque, autre que la date du jour :
Exemple : à quel jour de la semaine correspondra le 17 septembre 2016 ? Réponse donnée par date : un samedi
$ date "+%A %d %B %Y" -d "20160917"
samedi 17 septembre 2016
Et dans la chaîne passée en paramètre avec -d il est possible de faire des calculs sur les dates, comme par exemple ajouter un ou plusieurs jours :
$ date "+%A %d %B %Y" -d "20160917 1 days"
dimanche 18 septembre 2016
$ date "+%A %d %B %Y" -d "20160917 2 days"
lundi 19 septembre 2016
$ date "+%A %d %B %Y" -d "20160917 300 days"
vendredi 14 juillet 2017
Enfin, pour obtenir une liste de dates consécutives il suffit d'appeler la commande date dans une boucle for. La commande suivante affiche par exemple tous les jours de l'année scolaire 2015/2016 (300 jours consécutifs à partir du 1er septembre 2015) :
$ for ((i=0;i<300;i++)); do date "+%A %d %B %Y" -d "20150901 $i days"; done
mardi 01 septembre 2015
mercredi 02 septembre 2015
jeudi 03 septembre 2015
vendredi 04 septembre 2015
samedi 05 septembre 2015
dimanche 06 septembre 2015
lundi 07 septembre 2015
mardi 08 septembre 2015
mercredi 09 septembre 2015
jeudi 10 septembre 2015etc.
Vous voulez seulement les lundis, mardis et jeudis de l'année scolaire 2015/2016 ? Rien de plus simple, on va filtrer la sortie standard de la commande précédente par une expression régulière grâce à egrep afin de n'afficher que certaines lignes :
$ for ((i=0;i<300;i++)); do date "+%A %d %B %Y" -d "20150901 $i days"; done | egrep '(lundi|mardi|jeudi)'
mardi 01 septembre 2015
jeudi 03 septembre 2015
lundi 07 septembre 2015
mardi 08 septembre 2015
jeudi 10 septembre 2015
lundi 14 septembre 2015
mardi 15 septembre 2015
jeudi 17 septembre 2015
etc.
Et pour obtenir tous les jours sauf les samedis et les dimanches on utilise l'option -v d'egrep afin de ne pas afficher certaines lignes :
$ for ((i=0;i<300;i++)); do date "+%A %d %B %Y" -d "20150901 $i days"; done | egrep -v '(samedi|dimanche)'
mardi 01 septembre 2015
mercredi 02 septembre 2015
jeudi 03 septembre 2015
vendredi 04 septembre 2015
lundi 07 septembre 2015
mardi 08 septembre 2015
mercredi 09 septembre 2015
jeudi 10 septembre 2015
vendredi 11 septembre 2015
lundi 14 septembre 2015
mardi 15 septembre 2015
mercredi 16 septembre 2015
jeudi 17 septembre 2015
vendredi 18 septembre 2015etc.
Vous voulez connaître les 1er mai des 20 ans à venir ? Dans ce cas on va incrémenter la date d'année en année en partant d'un 1er mai :
$ for ((i=0;i<20;i++)); do date "+%A %d %B %Y" -d "20140501 $i year"; done
jeudi 01 mai 2014
vendredi 01 mai 2015
dimanche 01 mai 2016
lundi 01 mai 2017
mardi 01 mai 2018
mercredi 01 mai 2019
vendredi 01 mai 2020
samedi 01 mai 2021
dimanche 01 mai 2022
lundi 01 mai 2023
mercredi 01 mai 2024
jeudi 01 mai 2025
vendredi 01 mai 2026
samedi 01 mai 2027
lundi 01 mai 2028
mardi 01 mai 2029
mercredi 01 mai 2030
jeudi 01 mai 2031
samedi 01 mai 2032
dimanche 01 mai 2033
Et pour connaître les prochaines années bissextiles on part d'un 29 février et on incrémente d'année en année :
$ for ((i=0;i<20;i++)); do date "+%A %d %B %Y" -d "20000229 $i year"; done
mardi 29 février 2000
jeudi 01 mars 2001
vendredi 01 mars 2002
samedi 01 mars 2003
dimanche 29 février 2004
mardi 01 mars 2005
mercredi 01 mars 2006
jeudi 01 mars 2007
vendredi 29 février 2008
dimanche 01 mars 2009
lundi 01 mars 2010
mardi 01 mars 2011
mercredi 29 février 2012
vendredi 01 mars 2013
samedi 01 mars 2014
dimanche 01 mars 2015
lundi 29 février 2016
mercredi 01 mars 2017
jeudi 01 mars 2018
vendredi 01 mars 2019
En affichant seulement les lignes contenant la chaîne "29" on obtient seulement les années bissextiles :
$ for ((i=0;i<20;i++)); do date "+%A %d %B %Y" -d "20000229 $i year"; done | grep 29
mardi 29 février 2000
dimanche 29 février 2004
vendredi 29 février 2008
mercredi 29 février 2012
lundi 29 février 2016
Rappel : une année est bissextile si son numéro est multiple de 4 et pas multiple de 100, ou multiple de 400. Exemples : 1996 était bissextile, mais 1900 n'était pas bissextile, et 2000 était bien bissextile. Autres exemples : 2024 sera bissextile (multiple de 4), 2100 ne sera pas bissextile (multiple de 100), mais 2400 sera bien bissextile (multiple de 400).
Comment retrouver l'année d'une date donnée ? Exemple : vous savez qu'un évènement s'est produit un certain vendredi 15 septembre il y a quelques années mais vous ne savez plus exactement quelle année. Pour retrouver l'année on va ballayer tous les 15 septembre des années passées et ressortir seulement ceux correspondant à un vendredi :
$ for ((i=0;i<20;i++)); do date "+%A %d %B %Y" -d "19970915 $i year"; done | grep vendredi
vendredi 15 septembre 2000
vendredi 15 septembre 2006
Autre exemple avec le vendredi 14 juillet : pour quelle année au début des années 1980 le 14 juillet est-il tombé un vendredi ?
$ for ((i=0;i<20;i++)); do date "+%A %d %B %Y" -d "19700714 $i year"; done | grep vendredi
vendredi 14 juillet 1972
vendredi 14 juillet 1978
vendredi 14 juillet 1989
Comment générer un tableau HTML, c'est-à-dire encadrer chaque ligne par <tr><td> et </td></tr> ? Pour cela on va utiliser sed avec son support d'expréssions régulières étendues (option -r) afin de pouvoir remplacer un groupe (ici toute la ligne, représenté par \1 dans la chaîne de remplacement) :
$ for ((i=0;i<20;i++)); do date "+%A %d %B %Y" -d "$i days"; done | sed -r 's/^(.*)$/<tr><td>\1<\/td><\/tr>/'
<tr><td>dimanche 27 avril 2014</td></tr>
<tr><td>lundi 28 avril 2014</td></tr>
<tr><td>mardi 29 avril 2014</td></tr>
<tr><td>mercredi 30 avril 2014</td></tr>
<tr><td>jeudi 01 mai 2014</td></tr>
<tr><td>vendredi 02 mai 2014</td></tr>
<tr><td>samedi 03 mai 2014</td></tr>
<tr><td>dimanche 04 mai 2014</td></tr>
<tr><td>lundi 05 mai 2014</td></tr>
<tr><td>mardi 06 mai 2014</td></tr>
<tr><td>mercredi 07 mai 2014</td></tr>
<tr><td>jeudi 08 mai 2014</td></tr>
<tr><td>vendredi 09 mai 2014</td></tr>
<tr><td>samedi 10 mai 2014</td></tr>
<tr><td>dimanche 11 mai 2014</td></tr>
<tr><td>lundi 12 mai 2014</td></tr>
<tr><td>mardi 13 mai 2014</td></tr>
<tr><td>mercredi 14 mai 2014</td></tr>
<tr><td>jeudi 15 mai 2014</td></tr>
<tr><td>vendredi 16 mai 2014</td></tr>
Pour obtenir un véritable tableau HTML il ne reste plus qu'à encadrer l'ensemble des lignes générées entre <table> et </table>, ce qui peut biensûr se faire à la main après la génération, ou bien en ajoutant 2 commandes echo sur la ligne de commande (séparées de la boucle for par un point-virgule) :
$ echo "<table>" ; for ((i=0;i<20;i++)); do date "+%A %d %B %Y" -d "$i days"; done | sed -r 's/^(.*)$/<tr><td>\1<\/td><\/tr>/' ; echo "</table>"
<table>
<tr><td>dimanche 27 avril 2014</td></tr>
<tr><td>lundi 28 avril 2014</td></tr>
<tr><td>mardi 29 avril 2014</td></tr>
<tr><td>mercredi 30 avril 2014</td></tr>
<tr><td>jeudi 01 mai 2014</td></tr>
<tr><td>vendredi 02 mai 2014</td></tr>
<tr><td>samedi 03 mai 2014</td></tr>
<tr><td>dimanche 04 mai 2014</td></tr>
<tr><td>lundi 05 mai 2014</td></tr>
<tr><td>mardi 06 mai 2014</td></tr>
<tr><td>mercredi 07 mai 2014</td></tr>
<tr><td>jeudi 08 mai 2014</td></tr>
<tr><td>vendredi 09 mai 2014</td></tr>
<tr><td>samedi 10 mai 2014</td></tr>
<tr><td>dimanche 11 mai 2014</td></tr>
<tr><td>lundi 12 mai 2014</td></tr>
<tr><td>mardi 13 mai 2014</td></tr>
<tr><td>mercredi 14 mai 2014</td></tr>
<tr><td>jeudi 15 mai 2014</td></tr>
<tr><td>vendredi 16 mai 2014</td></tr>
</table>
Et voici ce tableau après mise en forme par votre navigateur :
| dimanche 27 avril 2014 |
| lundi 28 avril 2014 |
| mardi 29 avril 2014 |
| mercredi 30 avril 2014 |
| jeudi 01 mai 2014 |
| vendredi 02 mai 2014 |
| samedi 03 mai 2014 |
| dimanche 04 mai 2014 |
| lundi 05 mai 2014 |
| mardi 06 mai 2014 |
| mercredi 07 mai 2014 |
| jeudi 08 mai 2014 |
| vendredi 09 mai 2014 |
| samedi 10 mai 2014 |
| dimanche 11 mai 2014 |
| lundi 12 mai 2014 |
| mardi 13 mai 2014 |
| mercredi 14 mai 2014 |
| jeudi 15 mai 2014 |
| vendredi 16 mai 2014 |
Remarque : l'option -r est à sed ce que l'option -E est à grep : l'activation du support d'expressions régulières étendues. La commande egrep est un raccourcis remplaçant grep -E, et sed -r ne dispose pas de raccourcis équivalent. Afin d'utiliser les expressions régulières étendues on utilisera donc soit sed -r soit egrep.
Pour compter les jours dans notre calendrier on peut afficher la sortie standard grâce à nl qui affiche un fichier en numérotant les lignes :
$ for ((i=0;i<20;i++)); do date "+%A %d %B %Y" -d "20150901 $i days"; done | nl
1 mardi 01 septembre 2015
2 mercredi 02 septembre 2015
3 jeudi 03 septembre 2015
4 vendredi 04 septembre 2015
5 samedi 05 septembre 2015
6 dimanche 06 septembre 2015
7 lundi 07 septembre 2015
8 mardi 08 septembre 2015
9 mercredi 09 septembre 2015
10 jeudi 10 septembre 2015
11 vendredi 11 septembre 2015
12 samedi 12 septembre 2015
13 dimanche 13 septembre 2015
14 lundi 14 septembre 2015
15 mardi 15 septembre 2015
16 mercredi 16 septembre 2015
17 jeudi 17 septembre 2015
18 vendredi 18 septembre 2015
19 samedi 19 septembre 2015
20 dimanche 20 septembre 2015
Pour obtenir un fichier par semaine, on génère la liste des jours dans un fichier annee.txt en partant d'un lundi puis on va découper toutes les 7 lignes le fichier annee.txt en générant différents fichiers grâce à split :
$ for ((i=0;i<300;i++)); do date "+%A %d %B %Y" -d "20150831 $i days"; done > annee.txt
$ split -l 7 annee.txt semaine
Les fichiers obtenus se nomment semaineaa, semaineab, semaineac, semainead, etc. :
$ cat semaineaa
lundi 31 août 2015
mardi 01 septembre 2015
mercredi 02 septembre 2015
jeudi 03 septembre 2015
vendredi 04 septembre 2015
samedi 05 septembre 2015
dimanche 06 septembre 2015
$ cat semaineab
lundi 07 septembre 2015
mardi 08 septembre 2015
mercredi 09 septembre 2015
jeudi 10 septembre 2015
vendredi 11 septembre 2015
samedi 12 septembre 2015
dimanche 13 septembre 2015
$ cat semaineac
lundi 14 septembre 2015
mardi 15 septembre 2015
mercredi 16 septembre 2015
jeudi 17 septembre 2015
vendredi 18 septembre 2015
samedi 19 septembre 2015
dimanche 20 septembre 2015etc.
Pour compteur les semaines, c'est-à-dire numéroter seulement les lundis, on commence par mettre à plat l'ensemble des fichiers semainexx grâce à paste en choisissant le point-virgule comme séparateur :
$ paste -s -d ";" semaine*
Puis on affiche le résultat en numérotant les lignes grâce à nl :
$ paste -s -d ";" semaine* | nl
Puis on recrée les semaines d'origine en remplaçant le point-virgule par un retour à la ligne grâce à sed :
$ paste -s -d ";" semaine* | nl | sed 's/;/\n/g'
Enfin, on peut s'amuser à soigner la mise en forme, comme par exemple en ajoutant une tabulation en début de ligne et en séparant chaque semaine par une barre horizontale (chaîne =====================================) :
$ paste -s -d ";" semaine* | nl | sed 's/;/\n\t/g' | sed 's/ /=====================================\n/g'
Et le résultat final est :
=====================================
1 lundi 31 août 2015
mardi 01 septembre 2015
mercredi 02 septembre 2015
jeudi 03 septembre 2015
vendredi 04 septembre 2015
samedi 05 septembre 2015
dimanche 06 septembre 2015
=====================================
2 lundi 07 septembre 2015
mardi 08 septembre 2015
mercredi 09 septembre 2015
jeudi 10 septembre 2015
vendredi 11 septembre 2015
samedi 12 septembre 2015
dimanche 13 septembre 2015
=====================================
3 lundi 14 septembre 2015
mardi 15 septembre 2015
mercredi 16 septembre 2015
jeudi 17 septembre 2015
vendredi 18 septembre 2015
samedi 19 septembre 2015
dimanche 20 septembre 2015
=====================================
4 lundi 21 septembre 2015
mardi 22 septembre 2015
mercredi 23 septembre 2015
jeudi 24 septembre 2015
vendredi 25 septembre 2015
samedi 26 septembre 2015
dimanche 27 septembre 2015
=====================================
5 lundi 28 septembre 2015
mardi 29 septembre 2015etc.
Pour que notre calendrier soit complet il reste à calculer la date de tous les jours fériés pour une année quelconque. Pour cela voici un petit rappel :
Il existe en France 11 jours fériés par an, dont 8 à date fixe et 3 à date flottante :
Jour férié |
||
Les 8 jours fériés à date fixe ne posent aucun problème de repérage sur le calendrier, et on remarque que les 3 jours fériés à date flottante dépendent uniquement de la date du dimanche de Pâques : si on connaît la date de Pâques alors on en déduit les dates du lundi de Pâques, du jeudi de l'Ascension et du lundi de Pentecôte :
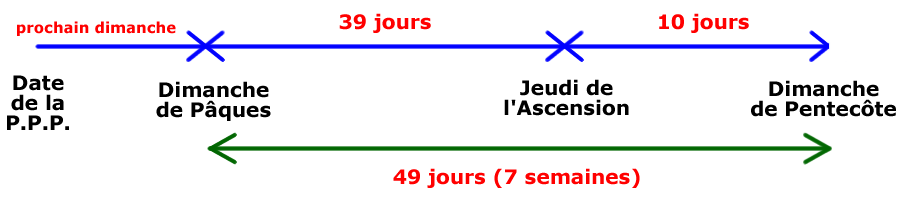
La question est alors la suivante : "Comment calculer, dans un shell Linux, la date de Pâques pour une année quelconque ?". Voici la solution :
La date du dimanche de Pâques a une définition de nature astronomique : il s'agit du premier dimanche qui suit la première pleine lune du printemps (la P.P.P.), soit à partir du 21 mars. Calculer la date de Pâques revient donc à déterminer la date de la première pleine lune suivant le 21 mars. Pour calculer la date de Pâques plusieurs algorithmes existent. Je n'en décrirais qu'un seul ici permettant de calculer instantanément la date de la Première Pleine lune du Printemps (P.P.P.) : sachant que le cycle lunaire est de 19 ans, vous divisez l'année par 19 puis vous comparez la partie décimale du résultat aux 19 valeurs du tableau ci-dessous.
| Partie décimale de année / 19 | Cette année la Première Pleine lune du Printemps est le |
| .000 | 14 AVRIL |
| .052 | 3 AVRIL |
| .105 | 23 MARS |
| .157 | 11 AVRIL |
| .210 | 31 MARS |
| .263 | 18 AVRIL |
| .315 | 8 AVRIL |
| .368 | 28 MARS |
| .421 | 16 AVRIL |
| .473 | 5 AVRIL |
| .526 | 25 MARS |
| .578 | 13 AVRIL |
| .631 | 2 AVRIL |
| .684 | 22 MARS |
| .736 | 10 AVRIL |
| .789 | 30 MARS |
| .842 | 17 AVRIL |
| .894 | 7 AVRIL |
| .947 | 27 MARS |
Exemple : quelle est la date la Première Pleine lune du Printemps (P.P.P.) pour l'année 2017 ? Calculons 2017 / 19 = 106,1578947368 dont on ne garde que la partie décimale 0.157. D'après la tableau ci-dessus 0.157 correspond au 11 avril. Le mardi 11 avril 2017 est donc la première pleine lune du printemps et le dimanche de Pâques est le prochain dimanche après le 11 avril 2017. On en déduit qu'en 2017 le dimanche de Pâques sera le dimanche 16 avril 2017. En ajoutant 39 jours au dimanche de Pâques on obtient le jeudi de l'Ascension : jeudi 25 mai 2017 et en ajoutant 49 jours au dimanche de Pâques on obtient le dimanche de Pentecôte : dimanche 4 juin 2017 (ou en ajoutant 50 jours au dimanche de Pâques on obtient le lundi de Pentecôte : lundi 5 juin 2017).
Remarques :
Le tableau ci-dessus donne la date de la première pleine lune du printemps (et non celle du dimanche de Pâques). Le dimanche de Pâques est le dimanche suivant la date indiquée.
Cet algorithme considérant qu'une année est bissextile tous les 4 ans sans exception il est valable seulement pour une année comprise entre 1901 et 2099 (car 1900 et 2100 ne sont pas bissextiles alors que 2000 était bissextile : entre 1901 et 2099 il y a eu une année bissextile régulièrement tous les 4 ans sans l'exception centennale) ce qui laisse tout de même suffisamment de marge pour prévoir les jours fériés des années à venir.
D'autres algorithmes (appelés algorithmes universels et non traités ici) existent pour calculer la date de Pâques (ou de la P.P.P.) quelque soit l'année en tenant compte de l'irrégularité des années bissextiles (multiple de 4 mais pas multiple de 100, ou multiple de 400).
Il existe donc 19 cas possibles pour la date de la P.P.P. (première pleine lune du printemps), car le cycle lunaire est de 19 ans.
Si la date de la P.P.P. est un dimanche il ne s'agit pas du dimanche de Pâques qui sera le dimanche suivant. C'est le cas par exemple en 2021 : 2021 / 19 = 106,36842105263 et d'après le tableau la P.P.P. correspondant à la partie décimale 0.368 est le 28 mars. Or le 28 mars 2021 est un dimanche. En 2021 le dimanche de Pâques sera donc le dimanche suivant le dimanche 28 mars 2021, soit le dimanche 4 avril 2021.
Les 2 dates extrêmes du dimanche de Pâques sont donc le 23 mars (P.P.P. le 22 mars qui serait un samedi) et le 25 avril (P.P.P. le 18 avril qui serait un dimanche) :
23 mars ≤ dimanche de Pâques ≤ 25 avril
On en déduit les dates extrêmes du jeudi de l'Ascension (39 jours après Pâques) et du dimanche de Pentecôte (49 jours après Pâques) :
01 mai ≤ jeudi de l'Ascension ≤ 03 juin
11 mai ≤ dimanche de Pentecôte ≤ 13 juin
Appliquons tout ça pour trouver les 3 jours fériés à dates flottantes dans un shell Linux :
Exemple 1 pour l'année 2014 :
Quelle est la date de la Première Pleine lune du Printemps en 2014 ? Divisons 2014 par 19 grâce à Python :
$ python -c "print 2014/19.0"
106.0En consultant le tableau ci-dessus on en déduit que la P.P.P. est le 14 avril 2014 (partie décimale .000). Quel est le jour de la semaine correspondant à la P.P.P. ?
$ date "+%A" -d "20140414"
lundiQuelle est la date de Pâques ? Demandons à date de nous sortir le prochain dimanche suivant la P.P.P. :
$ for ((i=1;i<=7;i++)); do date "+%A %d %B %Y" -d "20140414 $i days" | grep dimanche; done
dimanche 20 avril 2014Quelle est la date du lundi de Pâques ? Ajoutons 1 jour à la date de Pâques :
$ date "+%A %d %B %Y" -d "20140420 1 days"
lundi 21 avril 2014Quelle est la date du jeudi de l'Ascension ? Ajoutons 39 jours à la date de Pâques :
$ date "+%A %d %B %Y" -d "20140420 39 days"
jeudi 29 mai 2014Quelle est la date du dimanche de Pentecôte ? Ajoutons 49 jours à la date de Pâques :
$ date "+%A %d %B %Y" -d "20140420 49 days"
dimanche 08 juin 2014Quelle est la date du lundi de Pentecôte ? Ajoutons 50 jours à la date de Pâques :
$ date "+%A %d %B %Y" -d "20140420 50 days"
lundi 09 juin 2014
Exemple 2 pour l'année 2015 :
Quelle est la date de la Première Pleine lune du Printemps en 2015 ? Divisons 2015 par 19 grâce à Python :
$ python -c "print 2015/19.0"
106.052631579En consultant le tableau ci-dessus on en déduit que la P.P.P. est le 03 avril 2015 (partie décimale .052). Quel est le jour de la semaine correspondant à la P.P.P.?
$ date "+%A" -d "20150403"
vendrediQuelle est la date de Pâques ? Demandons à date de nous sortir le prochain dimanche suivant la P.P.P. :
$ for ((i=1;i<=7;i++)); do date "+%A %d %B %Y" -d "20150403 $i days" | grep dimanche; done
dimanche 05 avril 2015Quelle est la date du lundi de Pâques ? Ajoutons 1 jour à la date de Pâques :
$ date "+%A %d %B %Y" -d "20150405 1 days"
lundi 06 avril 2015Quelle est la date du jeudi de l'Ascension ? Ajoutons 39 jours à la date de Pâques :
$ date "+%A %d %B %Y" -d "20150405 39 days"
jeudi 14 mai 2015Quelle est la date du dimanche de Pentecôte ? Ajoutons 49 jours à la date de Pâques :
$ date "+%A %d %B %Y" -d "20150405 49 days"
dimanche 24 mai 2015Quelle est la date du lundi de Pentecôte ? Ajoutons 50 jours à la date de Pâques :
$ date "+%A %d %B %Y" -d "20150405 50 days"
lundi 25 mai 2015
Remarque : pour effectuer un calcul simple en ligne de commande sous Linux (comme ici pour diviser l'année par 19) il y a plusieurs solutions. On peut utiliser Python comme vu ci-dessus, mais on peut aussi utiliser :
Perl : perl -e "print(2015/19)"
La calculatrice GP : echo "2015/19.0" | gp
La calculatrice BC : echo "scale=3 ; 2015/19" | bc (scale=3 permet de demander 3 chiffres après la virgule : on obtient 106.052)
AWK : awk 'BEGIN{print 2015/19}' (dans ce cas on obtient la partie décimale arrondie à 0.053)
Pour obtenir une valeur décimale plus précise avec AWK on peut utiliser printf à la place de print :
awk 'BEGIN{printf("%f",2015/19)}'
On peut aussi utiliser simplement les possibilités de calcul du shell bash lui même, mais cette fois on doit faire les calculs en nombres entiers seulement :
echo $((2015000/19)) ce qui donne 106052 et on en déduit que la partie décimale de 2015/19 est 0.052
Pour aller plus loin, notre calendrier peut aussi indiquer les dates des changements d'heure. Rappel à ce sujet :
- on passe à l'heure d'été (+1 H) dans la nuit du dernier week-end de mars : dernier couple samedi + dimanche appartenant tous les deux au mois de mars
- on passe à l'heure d'hiver (-1 H) dans la nuit du dernier week-end d'octobre : dernier couple samedi + dimanche appartenant tous les deux au mois d'octobre
Plus précisément le changement d'heure doit être effectué le dimanche à 2 heures du matin. Ce dimanche est donc forcément compris :
- entre le 25 mars et le 31 mars pour le passage à l'heure d'été (+1H)
- entre le 25 octobre et le 31 octobre pour le passage à l'heure d'hiver (-1H)
Si le 31 du mois est un samedi on aura changé d'heure le week-end précédent, soit le dimanche 25. La recherche de la date du changement d'heure revient donc à rechercher le seul dimanche compris entre le 25 et le 31 du mois. Voyons comment le faire dans un shell Linux.
Exemple 1 : à quelle date passerons-nous à l'heure d'été pour l'année 2014 ? Pour cela balayons les 7 jours à partir du 25 mars afin de rechercher le seul dimanche :
$ for ((i=0;i<7;i++)); do date "+%A %d %B %Y" -d "20140325 $i day"; done | grep dimanche
dimanche 30 mars 2014
On en déduit qu'en 2014 c'est dans la nuit du samedi 29 mars 2014 au dimanche 30 mars 2014 qu'il faudra avancer nos montres d'une heure : à 2 H il sera 3 H.
Exemple 2 : à quelle date passerons-nous à l'heure d'hiver pour l'année 2014 ? Il s'agit du seul dimanche compris entre le 25 octobre et le 31 octobre :
$ for ((i=0;i<7;i++)); do date "+%A %d %B %Y" -d "20141025 $i day"; done | grep dimanche
dimanche 26 octobre 2014
On en déduit qu'en 2014 c'est dans la nuit du samedi 25 octobre 2014 au dimanche 26 octobre 2014 qu'il faudra retarder nos montres d'une heure : à 3 H il sera 2 H. Enfin, pour être vraiment complet, notre calendrier peut aussi indiquer les dates des phases principales de la lune. Nous n'afficherons ici que les dates de la pleine lune. Rappelons que le cycle de la lune dure 29.5 jours, ou plus précisément 29 jours 12 heures 44 minutes et 2.9 secondes. Nous arrondirons cette durée à 29j 12h 44 mn 3 s, soit 2551443 secondes (29*24*3600+12*3600+44*60+3=2551443). Cela signifie que la pleine lune se produit toutes les 2551443 secondes. Il suffit d'avoir une date de pleine lune dans l'année pour en déduire les dates des autres pleines lunes en ajoutant plusieurs fois 2551443 secondes à la date initiale. Et justement pour calculer la date de Pâques nous avons obtenu la date de la Première Pleine lune du Printemps (la P.P.P.), soit la première pleine lune suivant le 21 mars :
- en ajoutant 9 fois 2551443 secondes à la date de la P.P.P. nous pouvons obtenir les 9 pleines lunes d'avril à décembre (environ une par mois)
- en enlevant 3 fois 2551443 secondes à la P.P.P nous pouvons obtenir la date des pleines lunes de mars à janvier
Voyons concrêtement comme procéder pour retrouver dans un shell Linux toutes les dates des pleines lunes d'une année donnée :
Exemple pour l'année 2014 :
Quelle est la date de la Première Pleine lune du Printemps en 2014 ? Divisons 2014 par 19 grâce à Python :
$ python -c "print 2014/19.0"
106.0En consultant le tableau ci-dessus on en déduit que la P.P.P. est le 14 avril 2014 (partie décimale .000). Quel est le jour de la semaine correspondant à la P.P.P. ?
$ date "+%A %d %B %Y" -d "20140414"
lundi 14 avril 2014Quelle est la date de la prochaine pleine lune après le 14 avril 2014 ? Ajoutons 2551443 secondes à la date de la P.P.P :
$ date "+%A %d %B %Y" -d "20140414 2551443 second"
mardi 13 mai 2014Quelle est la date des 9 prochaines pleines lunes suivant la P.P.P. ? Ajoutons 9 fois 2551443 secondes à la date de la P.P.P grâce à une boucle for :
$ for ((i=0;i<9;i++)); do date "+%A %d %B %Y" -d "20140414 $(($i*2551443)) second" ; done
lundi 14 avril 2014
mardi 13 mai 2014
jeudi 12 juin 2014
vendredi 11 juillet 2014
dimanche 10 août 2014
lundi 08 septembre 2014
mercredi 08 octobre 2014
jeudi 06 novembre 2014
samedi 06 décembre 2014Quelle est la date des pleines lunes de janvier à mars précédent la P.P.P. ? Retranchons 3 fois 2551443 secondes à la date de la P.P.P grâce à une boucle for en passant en paramètre au programme date un nombre négatif :
$ for ((i=0;i<4;i++)); do date "+%A %d %B %Y" -d "20140414 $((-$i*2551443)) second" ; done
lundi 14 avril 2014
samedi 15 mars 2014
jeudi 13 février 2014
mercredi 15 janvier 2014Réunissons les résultats précédents pour obtenir les 12 pleines lunes de l'année 2014 (une pleine lune par mois, ou plus exactement tous les 29.5 jours ) :
mercredi 15 janvier 2014
jeudi 13 février 2014
samedi 15 mars 2014
lundi 14 avril 2014
mardi 13 mai 2014
jeudi 12 juin 2014
vendredi 11 juillet 2014
dimanche 10 août 2014
lundi 08 septembre 2014
mercredi 08 octobre 2014
jeudi 06 novembre 2014
samedi 06 décembre 2014
Remarque : cet algorithme simplifié de calcul des dates de pleine lune ne tiens pas compte des heures, et donne un résultat précis à un jour prés. En réalité, même si la valeur de 2551443 secondes est suffisamment précise, c'est l'heure exacte de la P.P.P. (Première Pleine lune du Printemps) qui est manquante : nous ne disposons que de la date de la P.P.P., sans information sur l'heure. Nos calculs considèrent donc que la P.P.P. a eu lieu à 0h0mn0s à la date de base (lundi 14 avril 2014 pour cet exemple). Or dans la pratique la P.P.P. a lieu entre 0h0mn0s et 23h59mn59s. La pleine lune peut donc en réalité se produire jusqu'à plusieurs heures après les dates indiquées. Par exmple pour le mois de juin 2014 le calendrier lunaire réel indique :
jeudi 12 juin 2014 : 98% visible
vendredi 13 juin 2014 : Pleine Lune
samedi 14 juin 2014 : 98% visible
En juin 2014 la réelle pleine lune est donc exactement le 13 juin 2014 mais notre algorithme simplifié nous a donné le 12 juin 2014. Pour être plus précis il faudrait, lors du calcul de la P.P.P., ajouter le calcul exact de l'heure de la pleine lune, sans se contenter seulement de la date comme on l'a fait pour déterminer la date de Pâques. Voilà, vous savez tout sur la génération d'un calendrier dans un shell Linux avec mise en forme du fichier texte de sortie, calcul des dates des jours fériés, calcul des changements d'heure et calcul des dates de pleine lune. Pour aller plus loin sur la génération automatique de calendrier voici deux autres applications de même type que j'ai programmées sur Gecif.net :
Le générateur de calendrier en PHP
Le générateur de calendrier en JavaScript
Le langage AWK
AWK est un langage de programmation spécialisé dans le traitement de fichier texte. Il réunit à lui seul ce que l'on peut faire avec Perl, grep et sed. Il s'agit d'un véritable langage de programmation (et non d'une simple commande comme grep) car il permet d'utiliser :
- des variables (non typées) afin de faire des calculs
- des fonctions prédéfinies pour le traitement des chaînes de caractères
- un support d'expressions régulières étendues
- des structures de contrôles classiques (boucles FOR, boucle While, if else, etc.) dont la syntaxe rappelle celle du langage C
AWK permet d'écrire de véritables scripts exécutables en utilisant le shebang #!/usr/bin/awk pour réaliser des programmes de traitement de fichiers textes ou des scripts CGI par exemple. Mais nous allons voir ici awk comme une simple commande Linux en un premier temps, sans détailler toute la syntaxe du langage.
Dans tous les exemples ci-dessous nous traiterons le fichier fic.txt contenant les 4 lignes suivantes contenant chacune 3 champs séparés par un point-virgule :
paul;23;p.durant@gecif.net
pierre;37;pierre@gecif.net
laure;28;l.dupont@gecif.net
vincent;19;v.martin@gecif.net
Voici quelques actions de base permettant de filtrer l'affichage du fichier fic.txt grâce à la commande awk :Afficher toutes les lignes du fichier fic.txt :
$ awk -F';' '{print}' fic.txt
paul;23;p.durant@gecif.net
pierre;37;pierre@gecif.net
laure;28;l.dupont@gecif.net
vincent;19;v.martin@gecif.net
Remarque : l'option -F d'awk permet de préciser le séparateur de champs utilisé sur chaque ligne du fichier (ici le point-virgule).Autre solution :
$ awk -F';' '{print $0}' fic.txt
paul;23;p.durant@gecif.net
pierre;37;pierre@gecif.net
laure;28;l.dupont@gecif.net
vincent;19;v.martin@gecif.net
Remarque : $0 représente la ligne entièreAfficher seulement le 1er champs de chaque lignes :
$ awk -F';' '{print $1}' fic.txt
paul
pierre
laure
vincent
Remarque : les différents champs sont repérés par $1, $2, $3, $4, etc.Afficher le nombre de champs contenu dans chaque ligne :
$ awk -F';' '{print NF}' fic.txt
3
3
3
3
Remarque : la variable NF d'awk représente le nombre de champs de la ligne courante. Afficher le numéro de chaque ligne :
$ awk -F';' '{print FNR}' fic.txt
1
2
3
4
Remarque : la variable FNR d'awk représente le nombre de ligne du fichier. Autre solution :
$ awk -F';' '{print NR}' fic.txt
1
2
3
4
Remarque : la variable NR d'awk représente le nombre de ligne déjà lues dans le fichier.
On va maintenant afficher seulement certaines lignes correspondant à divers critères. Pour cela on ajoute une condition avant l'accolade ouvrante afin d'applique l'action seulement à certaines lignes. Afficher seulement la ligne n°2 :
$ awk -F';' 'NR==2 {print $0}' fic.txt
pierre;37;pierre@gecif.net
Afficher les lignes 2 et 4 :
$ awk -F';' 'NR==2 || NR==4 {print $0}' fic.txt
pierre;37;pierre@gecif.net
vincent;19;v.martin@gecif.net
Afficher les lignes 2 à 4 :
$ awk -F';' 'NR==2 , NR==4 {print $0}' fic.txt
pierre;37;pierre@gecif.net
laure;28;l.dupont@gecif.net
vincent;19;v.martin@gecif.net
Afficher toutes les lignes jusqu'à la ligne 3 :
$ awk -F';' 'NR<=3 {print $0}' fic.txt
paul;23;p.durant@gecif.net
pierre;37;pierre@gecif.net
laure;28;l.dupont@gecif.net
Afficher les lignes dont le second champs est supérieur à 20 :
$ awk -F';' '$2>20 {print $0}' fic.txt
paul;23;p.durant@gecif.net
pierre;37;pierre@gecif.net
laure;28;l.dupont@gecif.net
On peut aussi filtrer les lignes par expression régulière. Afficher les lignes dont le premier champs commence par la lettre p:
$ awk -F';' '$1 ~ /^p/ {print $0}' fic.txt
paul;23;p.durant@gecif.net
pierre;37;pierre@gecif.net
Remarque : l'opérateur ~ vérifie la correspondance entre une chaîne (à gauche) est une expression régulière (à droite entre / et /).
Afficher les lignes ne correspondant pas à l'expression régulière :
$ awk -F';' '$1 !~ /^p/ {print $0}' fic.txt
laure;28;l.dupont@gecif.net
vincent;19;v.martin@gecif.net
Remarque : l'opérateur !~ permet d'exécuter une action si la chaîne ne correspond pas à l'expression régulière.Utilisons printf à la place de print afin de formater l'affichage en sortie.
Affichons les 3 champs séparés par un espace, les champs 1 et 3 étant des chaînes de caractères et le champs 2 étant un entier :
$ awk -F';' '{printf("%s %d %s\n",$1,$2,$3)}' fic.txt
paul 23 p.durant@gecif.net
pierre 37 pierre@gecif.net
laure 28 l.dupont@gecif.net
vincent 19 v.martin@gecif.net
Demandons à printf d'afficher le champs 1 sur 10 caractères justifiés à gauche, le champs 2 sur 6 caractères et le champs 3 sur 24 caractère justifiés à droite :
$ awk -F';' '{printf("%-10s %6d %24s\n",$1,$2,$3)}' fic.txt
paul 23 p.durant@gecif.net
pierre 37 pierre@gecif.net
laure 28 l.dupont@gecif.net
vincent 19 v.martin@gecif.net
Justifions le dernier champs à gauche (%-24s à la place de %24s) :
$ awk -F';' '{printf("%-10s %6d %-24s\n",$1,$2,$3)}' fic.txt
paul 23 p.durant@gecif.net
pierre 37 pierre@gecif.net
laure 28 l.dupont@gecif.net
vincent 19 v.martin@gecif.net
Espaçons 3ème champs du 2ème :
$ awk -F';' '{printf("%-10s %6d %-24s\n",$1,$2,$3)}' fic.txt
paul 23 p.durant@gecif.net
pierre 37 pierre@gecif.net
laure 28 l.dupont@gecif.net
vincent 19 v.martin@gecif.net
Grâce à la fonction gsub d'awk on peut remplacer une chaîne décrite par expression régulière par une autre chaîne.
Pour toutes les lignes, remplaçons les caratères @ par un caractère = :
$ awk -F';' '{gsub(/@/,"="); printf("%-10s %6d %-24s\n",$1,$2,$3)}' fic.txt
paul 23 p.durant=gecif.net
pierre 37 pierre=gecif.net
laure 28 l.dupont=gecif.net
vincent 19 v.martin=gecif.net
Pour toutes les lignes supprimons tout ce qui suit le caractère @ :
$ awk -F';' '{gsub(/@.*$/,""); printf("%-10s %6d %-24s\n",$1,$2,$3)}' fic.txt
paul 23 p.durant
pierre 37 pierre
laure 28 l.dupont
vincent 19 v.martin
Pour appliquer la substitution seulement à un champs (et non à la ligne entière), on le précise dans le 3ème paramètre de gsub :
$ awk -F';' '{gsub(/@.*$/,"",$3); printf("%-10s %6d %-24s\n",$1,$2,$3)}' fic.txt
paul 23 p.durant
pierre 37 pierre
laure 28 l.dupont
vincent 19 v.martin
Si on ne précise pas le nom du fichier texte à traiter sur la ligne de commande, le traitement s'appliquera à l'entrée standard.
Si on désire réaliser une action sans l'appliquer à un fichier ni à l'entrée standard on la place dans un bloc BEGIN :Affiche simplement bonjour à l'écran :
$ awk 'BEGIN{print "bonjour"}'
bonjour
Affiche les chiffres de 0 à 9 grâce à une boucle for :
$ awk 'BEGIN{for (i=0;i<10;i++) printf("%d\n",i)}'
0
1
2
3
4
5
6
7
8
9
En enlevant le BEGIN devant l'action elle s'appliquera à l'entrée standard. Si la commande n'est pas placée dans un tube elle attend la saisie au clavier d'une ligne. Cette ligne est $0. Si on saisie un nombre la commande suivante affichera tous les nombres de 0 à $0 :
$ awk '{for (i=0;i<$0;i++) printf("%d\n",i)}'
Utilisation des variables pour faire un calcul :
$ awk 'BEGIN{total=0; for (i=0;i<=15;i++) {total=total+i; printf("i = %2d total = %d\n",i,total)}}'
i = 0 total = 0
i = 1 total = 1
i = 2 total = 3
i = 3 total = 6
i = 4 total = 10
i = 5 total = 15
i = 6 total = 21
i = 7 total = 28
i = 8 total = 36
i = 9 total = 45
i = 10 total = 55
i = 11 total = 66
i = 12 total = 78
i = 13 total = 91
i = 14 total = 105
i = 15 total = 120
Nous venons de voir quelques possibilités de base de la commande awk, mais le langage awk est bien plus complet. Les fonctionnalités avancées d'awk seront vues et utilisées seulement en cas de besoin.
Génération automatique d'images
Maintenant qu'on sait modifier automatiquement tout fichier texte dans un shell Linux, une des applications possibles est la modification automatique d'images, ou la génération d'une série d'images en transformant une image de base en plusieurs variantes. Pour cela il faut commencer par enregistrer l'image de base dans un format enregistré dans un fichier texte. Plusieurs formats d'images utilisent un fichier texte ASCII modifiable par un simple éditeur de texte. Parmi eux il y a les formats de fichier XBM, XPM, VML, PGML, SVG, PS, EPS, etc. Les formats XBM et XPM décrivent chaque pixel d'une image dans une structure de donnée écrite en langage C. Les formats VML, PGML et SVG sont basés sur le langage à balise XML. Enfin le format PS décrit un document quelconque (image, texte, page, etc.) dans le langage PostScript utilisé par les imprimantes. Le format EPS (Encapsulated PostScript) est un fichier PostScript encapsulé, c'est-à-dire destiné à être intégré dans un autre fichier, et ne permet de décrire qu'une seule page (et non un document complet contrairement au format PS). Nous allons ici utiliser et manipuler en un premier temps des images dans le format PostScript (extension .ps) pour les raisons suivantes :
- le format PostScript est directement lié à LaTeX et au logiciel Xfig
- il est universel et multi-plateforme
-
chaque objet de l'image est décrit sur une ligne du fichier .ps : pour ajouter, supprimer ou modifier un objet sur l'image il suffit alors d'ajouter, de supprimer ou de modifier une ligne dans le fichier texte .ps, ce qui correspond parfaitement aux activités vues dans cet article
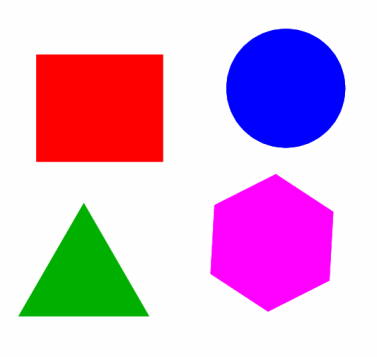
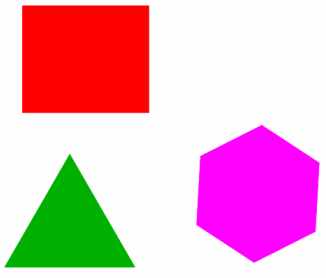
Partons d'une image dessinée dans le logiciel Xfig et contenant 4 objets : un rectangle rouge, un rond bleu, un triangle vert et un hexagone magenta :
Dans Xfig enregistrons cette image dans le fichier image.fig.
Les fichiers .fig étant des fichiers texte, affichons son contenu avec cat image.fig pour voir comment nos 4 formes géoméétriques y sont codées :
#FIG 3.2 Produced by xfig version 3.2.5c
Landscape
Center
Metric
A4
100.00
Single
-2
1200 2
1 3 0 1 1 1 50 -1 20 0.000 1 0.0000 8325 2250 1350 1350 8325 2250 9135 3330
2 2 0 1 4 4 50 -1 20 0.000 0 0 -1 0 0 5
2655 1485 5535 1485 5535 3915 2655 3915 2655 1485
2 3 0 1 13 13 50 -1 20 0.000 0 0 0 0 0 4
3735 4860 2254 7425 5216 7425 3735 4860
2 3 0 1 5 5 50 -1 20 0.000 0 0 0 0 0 7
9315 6615 9403 5057 8098 4202 6705 4905 6617 6463 7922 7318
9315 6615
Convertissons le fichier .fig en fichier PostScript .ps grâce à la commande fig2dev :
fig2dev -L ps -p 1 image.fig image.ps
Le fichier PostScript étant aussi un fichier texte, observons son contenu grâce à la commande cat image.ps :
%!PS-Adobe-3.0
%%Title: image.fig
%%Creator: fig2dev Version 3.2 Patchlevel 5e
%%CreationDate: Thu May 8 09:11:55 2014
%%Orientation: Portrait
%%Pages: 2
%%BoundingBox: 0 0 595 842
%%DocumentPaperSizes: a4
%Magnification: 1.0000
%%EndComments
%%BeginSetup
[{
%%BeginFeature: *PageRegion A4
<</PageSize [595 842]>> setpagedevice
%%EndFeature
} stopped cleartomark
%%EndSetup
%%BeginProlog
/$F2psDict 200 dict def
$F2psDict begin
$F2psDict /mtrx matrix put
/col-1 {0 setgray} bind def
/col0 {0.000 0.000 0.000 srgb} bind def
/col1 {0.000 0.000 1.000 srgb} bind def
/col2 {0.000 1.000 0.000 srgb} bind def
/col3 {0.000 1.000 1.000 srgb} bind def
/col4 {1.000 0.000 0.000 srgb} bind def
/col5 {1.000 0.000 1.000 srgb} bind def
/col6 {1.000 1.000 0.000 srgb} bind def
/col7 {1.000 1.000 1.000 srgb} bind def
/col8 {0.000 0.000 0.560 srgb} bind def
/col9 {0.000 0.000 0.690 srgb} bind def
/col10 {0.000 0.000 0.820 srgb} bind def
/col11 {0.530 0.810 1.000 srgb} bind def
/col12 {0.000 0.560 0.000 srgb} bind def
/col13 {0.000 0.690 0.000 srgb} bind def
/col14 {0.000 0.820 0.000 srgb} bind def
/col15 {0.000 0.560 0.560 srgb} bind def
/col16 {0.000 0.690 0.690 srgb} bind def
/col17 {0.000 0.820 0.820 srgb} bind def
/col18 {0.560 0.000 0.000 srgb} bind def
/col19 {0.690 0.000 0.000 srgb} bind def
/col20 {0.820 0.000 0.000 srgb} bind def
/col21 {0.560 0.000 0.560 srgb} bind def
/col22 {0.690 0.000 0.690 srgb} bind def
/col23 {0.820 0.000 0.820 srgb} bind def
/col24 {0.500 0.190 0.000 srgb} bind def
/col25 {0.630 0.250 0.000 srgb} bind def
/col26 {0.750 0.380 0.000 srgb} bind def
/col27 {1.000 0.500 0.500 srgb} bind def
/col28 {1.000 0.630 0.630 srgb} bind def
/col29 {1.000 0.750 0.750 srgb} bind def
/col30 {1.000 0.880 0.880 srgb} bind def
/col31 {1.000 0.840 0.000 srgb} bind defend/cp {closepath} bind def
/ef {eofill} bind def
/gr {grestore} bind def
/gs {gsave} bind def
/sa {save} bind def
/rs {restore} bind def
/l {lineto} bind def
/m {moveto} bind def
/rm {rmoveto} bind def
/n {newpath} bind def
/s {stroke} bind def
/sh {show} bind def
/slc {setlinecap} bind def
/slj {setlinejoin} bind def
/slw {setlinewidth} bind def
/srgb {setrgbcolor} bind def
/rot {rotate} bind def
/sc {scale} bind def
/sd {setdash} bind def
/ff {findfont} bind def
/sf {setfont} bind def
/scf {scalefont} bind def
/sw {stringwidth} bind def
/tr {translate} bind def
/tnt {dup dup currentrgbcolor
4 -2 roll dup 1 exch sub 3 -1 roll mul add
4 -2 roll dup 1 exch sub 3 -1 roll mul add
4 -2 roll dup 1 exch sub 3 -1 roll mul add srgb}
bind def
/shd {dup dup currentrgbcolor 4 -2 roll mul 4 -2 roll mul
4 -2 roll mul srgb} bind def
/DrawEllipse {
/endangle exch def
/startangle exch def
/yrad exch def
/xrad exch def
/y exch def
/x exch def
/savematrix mtrx currentmatrix def
x y tr xrad yrad sc 0 0 1 startangle endangle arc
closepath
savematrix setmatrix
} def/$F2psBegin {$F2psDict begin /$F2psEnteredState save def} def
/$F2psEnd {$F2psEnteredState restore end} def/pageheader {
save
newpath 0 842 moveto 0 0 lineto 595 0 lineto 595 842 lineto closepath clip newpath
-78.1 683.4 translate
$F2psBegin
10 setmiterlimit
0 slj 0 slc
0.06299 0.06299 sc
} bind def
/pagefooter {
$F2psEnd
restore
} bind def
%%EndProlog
%%Page: 1 1
%%BeginPageSetup
pageheader
1 -1 scale
%%EndPageSetup
%
% Fig objects follow
%
%
% here starts figure with depth 50
% Ellipse
7.500 slw
n 8325 2250 1350 1350 0 360 DrawEllipse gs col1 1.00 shd ef gr gs col1 s gr% Polyline
0 slj
0 slc
n 2655 1485 m 5535 1485 l 5535 3915 l 2655 3915 l
cp gs col4 1.00 shd ef gr gs col4 s gr
% Polyline
n 3735 4860 m 2254 7425 l 5216 7425 l
cp gs col13 1.00 shd ef gr gs col13 s gr
% Polyline
n 9315 6615 m 9403 5057 l 8098 4202 l 6705 4905 l 6617 6463 l 7922 7318 lcp gs col5 1.00 shd ef gr gs col5 s gr
% here ends figure;
pagefooter
showpage
%%Trailer
%EOF
Nous n'allons pas détailler ici tout le langage PostScript. Remarquons juste que dans le fichier PostScript les couleurs sont clairement nommées et définies dans le modèle RVB, puis chaque objets est décrit (couleur, coordonées, etc.). Les commentaires (lignes commençant par % et mise en valeur en rouge ci-dessus) permettant de se repérer dans le fichier (Ellipse pour le rond, Polyline pour les polygones, etc.). Sans être spécialiste du langage PostScript nous pouvons aisément constater qu'avec une observation poussée du fichier texte .ps et une maîtrise du traitement des fichiers texte en ligne de commande il est possible d'automatiser toutes sortes de modification sur l'image (changement de couleur, de taille, ajout ou supression d'objets, etc.).
Affichons l'image .ps gâce au visionneur de fichiers evince :
evince image.ps
On retrouve notre image telle qu'elle a été dessinée dans Xfig :
image.fig
Enfin pour convertir une image .ps en image .png on peut utiliser le programme convert d'ImageMagick :
convert image.ps image.png
Nous allons maintenat modifier certains éléments de l'image de base image.fig puis observer les modifications dans les fichiers texte .fig et .ps. Commençons par modifier seulement la taille du rectangle rouge dans Xfig puis enregistrons cette nouvelle image dans le fichier image1.fig :
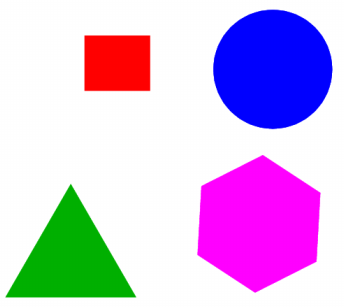
image1.fig
Affichons seulement les lignes qui ont changé entre le fichier d'origine image.fig et le nouveau fichier image1.fig :
cat image.fig image1.fig | sort | uniq -u
2655 1485 5535 1485 5535 3915 2655 3915 2655 1485
4050 1485 5535 1485 5535 2737 4050 2737 4050 1485
Affichons seulement les lignes qui ont changé entre le fichier PostScript d'origine image.ps et le nouveau fichier image1.ps sans afficher les commentaires commençant par %% :
cat image.ps image1.ps | sort | uniq -u | grep -v "%%"
n 2655 1485 m 5535 1485 l 5535 3915 l 2655 3915 l
n 4050 1485 m 5535 1485 l 5535 2737 l 4050 2737 l
On remarque que le rectangle est défini avec 4 points. En redimentionant le rectangle le coin supérieur droit n'a pas changé de position. Et en observant la différence entre les deux fichiers .ps on remarque en effet que :
- le 1er point a été modifié seulement en Xle 2ème point n'a pas été modifiéle 3ème point a été modifié seulement en Y
- le 4ème point a été modifié en X et en Y
En repartant du fichier d'origine image.fig modifions maintenant seulement la couleur du rond dans Xfig et enregistrons cette nouvelle image dans le fichier image2.fig :

image2.fig
Affichons seulement les lignes qui ont changé entre le fichier d'origine image.fig et le nouveau fichier image2.fig :
cat image.fig image2.fig | sort | uniq -u
1 3 0 1 1 1 50 -1 20 0.000 1 0.0000 8325 2250 1350 1350 8325 2250 9135 3330
1 3 0 1 6 6 50 -1 20 0.000 1 0.0000 8325 2250 1350 1350 8325 2250 9675 2250
Affichons seulement les lignes qui ont changé entre le fichier PostScript d'origine image.ps et le nouveau fichier image2.ps sans afficher les commentaires commençant par %% :
cat image.ps image2.ps | sort | uniq -u | grep -v "%%"
n 8325 2250 1350 1350 0 360 DrawEllipse gs col1 1.00 shd ef gr gs col1 s gr
n 8325 2250 1350 1350 0 360 DrawEllipse gs col6 1.00 shd ef gr gs col6 s gr
Ici le changement est clair : la figure est passée de la couleur col1 à la couleur col6. On remarque aussi que l'angle du disque écrit en clair et en degré : 360. En modifiant cette valeur dans le fichier PostScript on modifie l'angle du disque ce qui devrait permettre d'obtenir différents secteurs angulaires. En repartant du fichier d'origine image.fig modifions maintenant seulement la position de l'hexagone dans Xfig (sans modifier sa taille ni sa couleur) et enregistrons cette nouvelle image dans le fichier image3.fig :
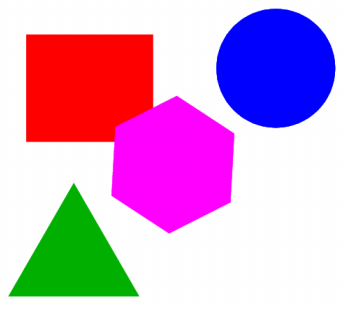
image3.fig
Affichons seulement les lignes qui ont changé entre le fichier d'origine image.fig et le nouveau fichier image3.fig :
cat image.fig image3.fig | sort | uniq -u
7292 5293
7292 5293 7380 3735 6075 2880 4682 3583 4594 5141 5899 5996
9315 6615
9315 6615 9403 5057 8098 4202 6705 4905 6617 6463 7922 7318
Affichons seulement les lignes qui ont changé entre le fichier PostScript d'origine image.ps et le nouveau fichier image3.ps sans afficher les commentaires commençant par %% :
cat image.ps image3.ps | sort | uniq -u | grep -v "%%"
n 7292 5293 m 7380 3735 l 6075 2880 l 4682 3583 l 4594 5141 l 5899 5996 l
n 9315 6615 m 9403 5057 l 8098 4202 l 6705 4905 l 6617 6463 l 7922 7318 l
L'hexagone est défini par 6 points qui ont tous les 6 changé de coordonnées lors du déplacement de l'hexagone.
En repartant du fichier d'origine image.fig modifions maintenant seulement l'orientation du triangle dans Xfig en lui faisant subir une rotation de 30 degrés et enregistrons cette nouvelle image dans le fichier image4.fig :

image4.fig
Affichons seulement les lignes qui ont changé entre le fichier d'origine image.fig et le nouveau fichier image4.fig :
cat image.fig image4.fig | sort | uniq -u
3735 4860 2254 7425 5216 7425 3735 4860
5216 4463 2651 5944 5216 7425 5216 4463
Affichons seulement les lignes qui ont changé entre le fichier PostScript d'origine image.ps et le nouveau fichier image4.ps sans afficher les commentaires commençant par %% :
cat image.ps image4.ps | sort | uniq -u | grep -v "%%"
-78.1 683.4 translate
-90.6 683.4 translate
n 3735 4860 m 2254 7425 l 5216 7425 l
n 5216 4463 m 2651 5944 l 5216 7425 l
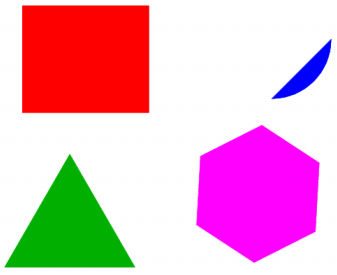
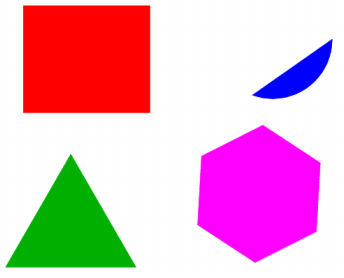
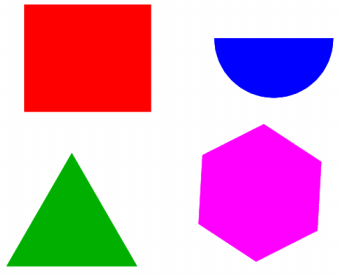
La rotation du triangle a été effectuée autour d'un de ses sommets qui n'a donc pas changé de coordonnées. Mais en plus des 2 sommets déplacés, on constate que la ligne contenant translate a été aussi modifiée lors de la rotation de 30 degrés du triangle. Application à la génération automatique d'images : en repartant de l'image d'origine, générons 37 images différentes, nommées angle_00.ps à angle_360.ps en modifiant l'angle du disque bleu de 0° à 360° de 10° en 10°. La ligne de commande suivante effectue une telle génération grâce à une simple boucle for et à sed qui remplace le 360 par les différentes valeurs :
for ((i=0;i<=36;i++)); do cat image.ps | sed "s/360/$(($i*10))/" > angle_$(($i))0.ps ; done
Voici 6 images parmi la série des 37 images obtenues :
|
|
|
|
 angle_250.ps |
 angle_360.ps |
Même si le résultat n'est pas forcément celui que l'on attendait, cette expérience a prouvé qu'un traitement avancé de fichier texte sous Linux pouvait aboutir à la génération automatique d'images. Pour aller plus loin il reste à se plonger dans le langage PostScript afin de bien maîtriser les paramètres de chaque fonction, puis à utiliser awk afin d'effectuer des traitements fins et poussés sur les fichiers PostScript, en sélectionnant certains champs de certaines lignes des fichiers texte.
Autre exemple en modifiant cette fois le contenu d'un fichier SVG. On part d'un bouton dessiné dans Xfig :

Ce bouton possède 4 éléments de base :
- un texte ("Lien")
- une couleur de cadre (bleu, codé #0000ff)
- une couleur de fond (rouge, codé #ff0000)
- une couleur de texte (jaune, codé #ffff00)
On l'enregistre dans le fichier bouton.svg (fichier texte au format XML) dont le contenu est :
<?xml version="1.0" standalone="no"?>
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN"
"http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd">
<!-- Creator: fig2dev Version 3.2 Patchlevel 5e -->
<!-- CreationDate: Thu May 8 17:05:12 2014 -->
<!-- Magnification: 1.050 -->
<svg xmlns="http://www.w3.org/2000/svg"
xmlns:xlink="http://www.w3.org/1999/xlink"
width="3.4in" height="2.2in"
viewBox="3075 3075 4101 2637">
<g style="stroke-width:.025in; fill:none">
<!-- Line: box -->
<rect x="3165" y="3165" width="3921" height="2456" rx="157"
style="stroke:#0000ff;stroke-width:111;
stroke-linejoin:miter; stroke-linecap:butt;
fill:#ff0000;
"/>
<!-- Text -->
<text xml:space="preserve" x="4488" y="4299" fill="#ffff00" font-family="AvantGarde" font-style="normal" font-weight="bold" font-size="578" text-anchor="start">Lien </text>
</g>
</svg>
On retrouve facilement chacun des 4 éléments de base dans ce fichier texte .SVG au format XML (mis en rouge ci-dessus). En modifiant le contenu du fichier SVG grâce à l'éditeur de flux textuel non interactif sed on va modifier les éléments de base afin de changer certains paramètres de l'image.
Remplaçons le texte Lien par le texte Gecif, puis observons immédiatement le résultat avec la visionneuse eog (Eye of GNOME) :
cat bouton.svg | sed "s/Lien/Gecif/" > toto.svg ; eog toto.svg
Modifions en plus la couleur du fond :
cat bouton.svg | sed "s/Lien/Gecif/" | sed "s/#ff0000/#128469/" > toto.svg ; eog toto.svg
Modifions en plus la couleur du cadre :
cat bouton.svg | sed "s/Lien/Gecif/" | sed "s/#ff0000/#128469/" | sed "s/#0000ff/#F72910/" > toto.svg ; eog toto.svg
Le fait d'enregistrer le résultat dans le fichier provisoire toto.svg et de le visionner immédiatement permet de tester rapidement différentes couleurs afin de retenir seulement les meilleurs rendus. Imaginons maintenant que nous voulions générer automatiquement un ensemble de boutons tous dérivés du bouton de base. On désire utiliser :
- 4 textes différents : Lien 1, Lien 2, Lien 3 et Lien 4
- 4 couleurs de fond : #00FFFF, #FF00FF, #0000CC et #333333
- 4 couleurs de cadre : #999999, #FFCC00, #FF3300 et #33CC00
- 4 couleurs de texte : #336600, #663300, #6600CC et #9999CC
On souhaite utiliser toutes les combinaisons possibles : 4x4x4x4=256 boutons différentsEn imbriquant 4 boucles for dans le shell Linux nous allons obtenir instantanément nos 256 fichiers images .svg des 256 boutons :
$ n=1 ; for i in 1 2 3 4 ; do for fond in 00ffff ff00ff 0000cc 333333 ; do for cadre in 999999 ffcc00 ff3300 33cc00 ; do for texte in 336600 663300 6600cc 9999cc ; do cat bouton.svg | sed "s/Lien/Lien $i/" | sed "s/#ff0000/#$fond/" | sed "s/#0000ff/#$cadre/" | sed "s/#ffff00/#$texte/" > bouton_$(($n)).svg ; n=$(($n+1)) ; done ; done ; done ; done ;
Ça c'est de la ligne de commande ! Remarquez la variable n qui permet de numéroter les 256 fichiers de sortie de bouton_1.svg à bouton_256.svg sans utiliser les variables des boucles for. Cet exemple a montré comment, en utilisant l'éditeur de flux non intéractif sed et les possibilités du shell Linux (redirection, variables, boucle for, etc.), on peut générer un ensemble d'images. Mais nous n'avons encore rien fait, beaucoup d'autres paramètres de l'images sont ainsi modifiables (taille, forme des objets, épaisseur des traits, transparence, etc.) et nous n'avons toujours pas utiliser awk ni make qui pourrait bien nous aider pour la génération automatique de centaines de fichiers images.
Générateur de questions et d'images pour QCM
Exemple d'application : modifier automatiquement les valeurs des composants sur un schéma électronique. On part du schéma suivant dessiné sous Xfig et représentant 3 condensateurs. Les 3 valeurs numériques des capacités sont pour l'instant notées aaaa, bbbb, et cccc (toutes les 3 en nano farad) :
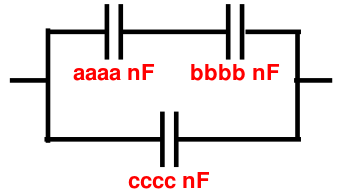
Enregistrons ce schéma dans le format SVG sous le nom condensateur.svg :
<?xml version="1.0" standalone="no"?>
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN"
"http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd">
<!-- Creator: fig2dev Version 3.2 Patchlevel 5e -->
<!-- CreationDate: Mon May 12 15:42:08 2014 -->
<!-- Magnification: 1.050 -->
<svg xmlns="http://www.w3.org/2000/svg"
xmlns:xlink="http://www.w3.org/1999/xlink"
width="3.8in" height="2.1in"
viewBox="2730 2447 4507 2576">
<g style="stroke-width:.025in; fill:none">
<!-- Line -->
<polyline points="4110,3259
4110,2503
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="4299,3259
4299,2503
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="5763,3259
5763,2503
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="5952,3259
5952,2503
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="4866,4724
4866,3968
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="5055,4724
5055,3968
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="5999,2881
6755,2881
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="5055,4346
6755,4346
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="4866,4346
3259,4346
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="6708,2881
6708,4346
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="4299,2881
5763,2881
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="3307,2881
4062,2881
4110,2881
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="3307,4393
3307,2834
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="3307,3543
2787,3543
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Line -->
<polyline points="7181,3543
6661,3543
" style="stroke:#000000;stroke-width:63;
stroke-linejoin:miter; stroke-linecap:butt;
"/>
<!-- Text -->
<text xml:space="preserve" x="4960" y="5007" fill="#ff0000" font-family="Helvetica" font-style="normal" font-weight="bold" font-size="303" text-anchor="middle">cccc nF</text>
<!-- Text -->
<text xml:space="preserve" x="4204" y="3543" fill="#ff0000" font-family="Helvetica" font-style="normal" font-weight="bold" font-size="303" text-anchor="middle">aaaa nF</text>
<!-- Text -->
<text xml:space="preserve" x="5858" y="3543" fill="#ff0000" font-family="Helvetica" font-style="normal" font-weight="bold" font-size="303" text-anchor="middle">bbbb nF</text>
</g>
</svg>
Nous voulons maintenant donner à chaque condensateurs 4 valeurs différentes :
Valeur par défaut |
||||
On souhaite utiliser toutes les combinaisons possibles : 4x4x4=64 schémas différentsAvec 3 boucles for imbriquées dans le shell Linux on obtient les 64 images au format png nommées condensateur_1.png à condensateur_64.png :
$ n=1 ; for a in 4 6 8 10 ; do for b in 6 8 12 16 ; do for c in 1 2 3 4 ; do cat condensateur.svg | sed "s/aaaa/$a/" | sed "s/bbbb/$b/" | sed "s/cccc/$c/" > condensateur_$(($n)).svg ; convert condensateur_$(($n)).svg condensateur_$(($n)).png ; echo "$a;$b;$c;condensateur_$n.png" >> condensateur.txt ; n=$(($n+1)) ; done ; done ; done ;
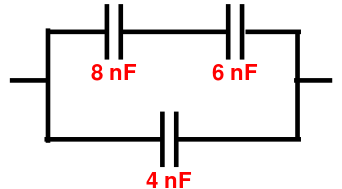
Voici par exemple le fichier condensateur_36.png :
En plus des 64 fichiers images (en svg et en png) on obteint aussi le fichier texte condensateur.txt contenant les valeurs de chacun des 3 condensateurs ainsi que le nom du fichier png correspondant :
4;6;1;condensateur_1.png
4;6;2;condensateur_2.png
4;6;3;condensateur_3.png
4;6;4;condensateur_4.png
4;8;1;condensateur_5.png
4;8;2;condensateur_6.png
4;8;3;condensateur_7.png
4;8;4;condensateur_8.png
4;12;1;condensateur_9.png
4;12;2;condensateur_10.png
4;12;3;condensateur_11.png
4;12;4;condensateur_12.png
4;16;1;condensateur_13.png
4;16;2;condensateur_14.png
4;16;3;condensateur_15.png
4;16;4;condensateur_16.png
6;6;1;condensateur_17.png
6;6;2;condensateur_18.png
6;6;3;condensateur_19.png
6;6;4;condensateur_20.png
6;8;1;condensateur_21.png
6;8;2;condensateur_22.png
6;8;3;condensateur_23.png
6;8;4;condensateur_24.png
6;12;1;condensateur_25.png
6;12;2;condensateur_26.png
6;12;3;condensateur_27.png
6;12;4;condensateur_28.png
6;16;1;condensateur_29.png
6;16;2;condensateur_30.png
6;16;3;condensateur_31.png
6;16;4;condensateur_32.png
8;6;1;condensateur_33.png
8;6;2;condensateur_34.png
8;6;3;condensateur_35.png
8;6;4;condensateur_36.png
8;8;1;condensateur_37.png
8;8;2;condensateur_38.png
8;8;3;condensateur_39.png
8;8;4;condensateur_40.png
8;12;1;condensateur_41.png
8;12;2;condensateur_42.png
8;12;3;condensateur_43.png
8;12;4;condensateur_44.png
8;16;1;condensateur_45.png
8;16;2;condensateur_46.png
8;16;3;condensateur_47.png
8;16;4;condensateur_48.png
10;6;1;condensateur_49.png
10;6;2;condensateur_50.png
10;6;3;condensateur_51.png
10;6;4;condensateur_52.png
10;8;1;condensateur_53.png
10;8;2;condensateur_54.png
10;8;3;condensateur_55.png
10;8;4;condensateur_56.png
10;12;1;condensateur_57.png
10;12;2;condensateur_58.png
10;12;3;condensateur_59.png
10;12;4;condensateur_60.png
10;16;1;condensateur_61.png
10;16;2;condensateur_62.png
10;16;3;condensateur_63.png
10;16;4;condensateur_64.png
Il reste maintenant à convertir ce fichier texte condensateur.txt en fichier de QCM. Pour cela nous allons utiliser awk. L'ensemble des actions awk étant assez long nous allons les écrire dans un fichier de script nommé qcm.awk :
# Script AWK réalisé le 13 mai 2014 par Jean-Christophe MICHEL
# www.gecif.net
# Configure le séparateur dans le bloc BEGIN
BEGIN { FS=";" }# Bloc contenant les actions à réaliser sur toutes les lignes
{
# Calcule la bonne réponse et 3 mauvaises réponses
vrai=(($1*$2)/($1+$2))+$3
faux1=($1+$2)/($1*$2)+$3
faux2=(($1+$2)*$3)/($1+$2+$3)
faux3=($1+$2)/$3
if (!((vrai!=faux1) && (vrai!=faux2) && (vrai!=faux3) && (faux1!=faux2) && (faux3!=faux2) && (faux1!=faux3)))
{
# Formule suplémentaire en cas de réponses identiques :
faux3=8
}if ((vrai!=faux1) && (vrai!=faux2) && (vrai!=faux3) && (faux1!=faux2) && (faux3!=faux2) && (faux1!=faux3))
{
# Affiche le QCM si les 4 réponses sont différentes :
printf("quest(\"Quelle est la capacité équivalente de ce montage ?//a\");\nrep(\"(o) %.2f nF\");\nrep(\"( ) %.2f nF\");\nrep(\"( ) %.2f nF\");\nrep(\"( ) %.2f nF\");\nsch(\"images/%s\",\"342\",\"189\");\n",vrai,faux1,faux2,faux3,$4)
}
else
{
# Message en cas de réponses identiques afin de modifier la formule suplémentaire ci-dessus :
printf("!! ATTENTION REPONSES IDENTIQUES !! vrai : %.2f faux1 : %.2f faux2 : %.2f faux3 : %.2f\n",vrai,faux1,faux2,faux3)
}}
La ligne de commande suivante permet de vérifier si toutes les réponses sont bien différentes (dans ce cas aucun message affiché) :
awk -f qcm.awk < condensateur.txt | grep ATTENTION
La ligne de commande suivante envoie sur l'entrée standard du script qcm.awk les lignes du fichier condensateur.txt, le script qcm.awk traite chacune des lignes reçues, puis sa sortie standard est redirigée vers le fichier texte qcm.txt :
awk -f qcm.awk < condensateur.txt > qcm.txt
Et voici le contenu du fichier qcm.txt : il contient les 64 questions du QCM utilisant les 64 images différentes générées dynamiquement :
quest("Quelle est la capacité équivalente de ce montage ?//a");
rep("(o) 3.40 nF");
rep("( ) 1.42 nF");
rep("( ) 0.91 nF");
rep("( ) 10.00 nF");
sch("images/condensateur_1.png","342","189");
quest("Quelle est la capacité équivalente de ce montage ?//a");
rep("(o) 4.40 nF");
rep("( ) 2.42 nF");
rep("( ) 1.67 nF");
rep("( ) 5.00 nF");
sch("images/condensateur_2.png","342","189");
quest("Quelle est la capacité équivalente de ce montage ?//a");
rep("(o) 5.40 nF");
rep("( ) 3.42 nF");
rep("( ) 2.31 nF");
rep("( ) 3.33 nF");
sch("images/condensateur_3.png","342","189");
quest("Quelle est la capacité équivalente de ce montage ?//a");
rep("(o) 6.40 nF");
rep("( ) 4.42 nF");
rep("( ) 2.86 nF");
rep("( ) 2.50 nF");
sch("images/condensateur_4.png","342","189");
quest("Quelle est la capacité équivalente de ce montage ?//a");
rep("(o) 3.67 nF");
rep("( ) 1.38 nF");
rep("( ) 0.92 nF");
rep("( ) 12.00 nF");
sch("images/condensateur_5.png","342","189");
quest("Quelle est la capacité équivalente de ce montage ?//a");
rep("(o) 4.67 nF");
rep("( ) 2.38 nF");
rep("( ) 1.71 nF");
rep("( ) 6.00 nF");
sch("images/condensateur_6.png","342","189");
etc.
L'utilisation du fichier intermédiaire condensateur.txt n'est pas obligatoire : on aurait très bien pu rediriger la sortie standard des boucles for directement vers l'entrée standard du script qcm.awk :
$ n=1 ; for a in 4 6 8 10 ; do for b in 6 8 12 16 ; do for c in 1 2 3 4 ; do cat condensateur.svg | sed "s/aaaa/$a/" | sed "s/bbbb/$b/" | sed "s/cccc/$c/" > condensateur_$(($n)).svg ; convert condensateur_$(($n)).svg condensateur_$(($n)).png ; echo "$a;$b;$c;condensateur_$n.png" | awk -f qcm.awk ; n=$(($n+1)) ; done ; done ; done ;
Et en récupérant la sortie standard du script qcm.awk dans le fichier qcm.txt on génère directement avec une seule ligne de commande les 64 images et les 64 questions associées :
$ rm qcm.txt ; n=1 ; for a in 4 6 8 10 ; do for b in 6 8 12 16 ; do for c in 1 2 3 4 ; do cat condensateur.svg | sed "s/aaaa/$a/" | sed "s/bbbb/$b/" | sed "s/cccc/$c/" > condensateur_$(($n)).svg ; convert condensateur_$(($n)).svg condensateur_$(($n)).png ; echo "$a;$b;$c;condensateur_$n.png" | awk -f qcm.awk >> qcm.txt ; n=$(($n+1)) ; done ; done ; done ;
Autre exemple permettant d'obtenir 64 images et 64 questions de QCM avec une seule ligne de commande utilisant un script AWK dans un shell Linux : On part du schéma suivant dessiné dans Xfig et enregistré sous le nom condensateur.svg :
On utilise le script qcm.awk suivant :
# Script AWK réalisé le 13 mai 2014 par Jean-Christophe MICHEL
# www.gecif.net
BEGIN {
FS=";"
}{
# Calcule la bonne réponse et 3 mauvaises réponses :
vrai=(($1+$2)*$3)/($1+$2+$3)
faux1=($1*$2)/($1+$2)+$3if ($5 % 4==0) {
faux2=(($1+$2)/($1*$2))+$3
faux3=vrai-2.37 }if ($5 % 4==1) {
faux2=vrai-1
faux3=vrai+4.81 }if ($5 % 4==2) {
faux2=vrai+3.68
faux3=vrai-1.96 }if ($5 % 4==3) {
faux2=vrai+4.62
faux3=vrai+3.17 }if ((vrai!=faux1) && (vrai!=faux2) && (vrai!=faux3) && (faux1!=faux2) && (faux3!=faux2) && (faux1!=faux3))
{
# Affiche le QCM si les 4 réponses sont différentes :
printf("quest(\"Quelle est la capacité équivalente de ce montage ?//a\");\nrep(\"(o) %.2f nF\");\nrep(\"( ) %.2f nF\");\nrep(\"( ) %.2f nF\");\nrep(\"( ) %.2f nF\");\nsch(\"images/%s\",\"324\",\"171\");\n",vrai,faux1,faux2,faux3,$4)
} else {
# Message en cas de réponses identiques afin de modifier le calcul des fausses réponses ci-dessus :
printf("!! ATTENTION REPONSES IDENTIQUES !! vrai : %.2f faux1 : %.2f faux2 : %.2f faux3 : %.2f\n",vrai,faux1,faux2,faux3)
}}
Ce nouveau script AWK reçoit en 5ème paramètre la valeur de la variable $n de la ligne de commande (65<=$n<=128 pour cet exemple) et calcule le modulo 4 de $n afin de varier le calcul des fausses réponses toutes les 4 questions. Ceci évite que la bonne réponse soit toujours la plus grande, toujours la plus petite, ou encore toujours la seconde en classant les 4 réponses dans l'ordre croissant. La ligne de commande suivante envoie une ligne à 5 champs au script qcm.awk et génère les 64 fichiers images (nommées condensateur_65.png à condensateur_128.png) et les 64 questions du QCM dans le fichier qcm.txt :
$ rm qcm.txt;n=65;for a in 1 3 5 7 ; do for b in 2 4 6 8 ; do for c in 5 6 9 15 ; do cat condensateur1.svg | sed "s/aaaa/$a/" | sed "s/bbbb/$b/" | sed "s/cccc/$c/" > condensateur_$(($n)).svg ; convert condensateur_$((n)).svg condensateur_$((n)).png ; echo "$a;$b;$c;condensateur_$n.png;$n" | awk -f qcm.awk >> qcm.txt ;n=$(($n+1)) ; done ;done ;done ;
Et voici le contenu du fichier qcm.txt généré :
quest("Quelle est la capacité équivalente de ce montage ?//a");
rep("(o) 1.88 nF");
rep("( ) 5.67 nF");
rep("( ) 0.88 nF");
rep("( ) 6.68 nF");
sch("images/condensateur_65.png","324","171");
quest("Quelle est la capacité équivalente de ce montage ?//a");
rep("(o) 2.00 nF");
rep("( ) 6.67 nF");
rep("( ) 5.68 nF");
rep("( ) 0.04 nF");
sch("images/condensateur_66.png","324","171");
quest("Quelle est la capacité équivalente de ce montage ?//a");
rep("(o) 2.25 nF");
rep("( ) 9.67 nF");
rep("( ) 6.87 nF");
rep("( ) 5.42 nF");
sch("images/condensateur_67.png","324","171");
quest("Quelle est la capacité équivalente de ce montage ?//a");
rep("(o) 2.50 nF");
rep("( ) 15.67 nF");
rep("( ) 16.50 nF");
rep("( ) 0.13 nF");
sch("images/condensateur_68.png","324","171");
quest("Quelle est la capacité équivalente de ce montage ?//a");
rep("(o) 2.50 nF");
rep("( ) 5.80 nF");
rep("( ) 1.50 nF");
rep("( ) 7.31 nF");
sch("images/condensateur_69.png","324","171");
etc.
Conclusion